内存管理
内存管理
-
物理内存 只有内存管理模块可以操作
-
虚拟地址 每个进程看到的是独立的、互不干扰的虚拟地址空间
- 内核空间 在高地址 内核 同一个内核空间
- 用户空间 在低地址 普通进程 独占整个空间
-
用户态内存构成
- Text Segment 存放二进制可执行代码
- Data Segment 存放静态常量
- BSS Segment 未初始化的静态变量
- 堆(Heap)段 动态分配内存
- Memory Mapping Segment 文件映射进内存
- 栈(Stack)地址段 函数调用的函数栈
-
可以查看进程内存空间的布局的命令
cat /proc/<pid>/map pmap <pid> -
物理内存和虚拟地址映射
- 分段机制 Linux中段只被用于访问控制和内存保护。
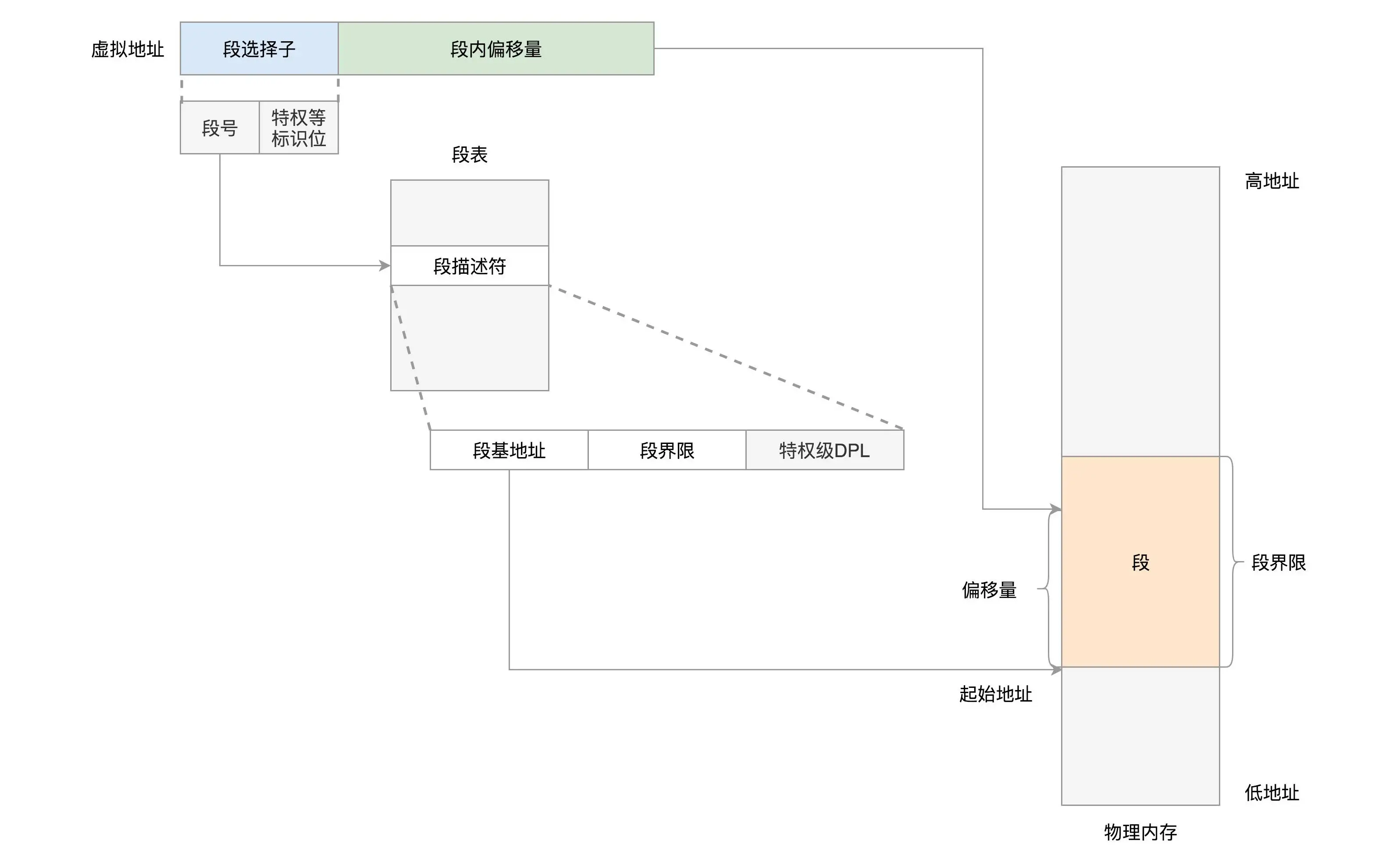
段选择子和段内偏移量,段基地址加上段内偏移量得到物理内存地址。
- 分页机制 Linux 主要使用分页的机制 多级页表
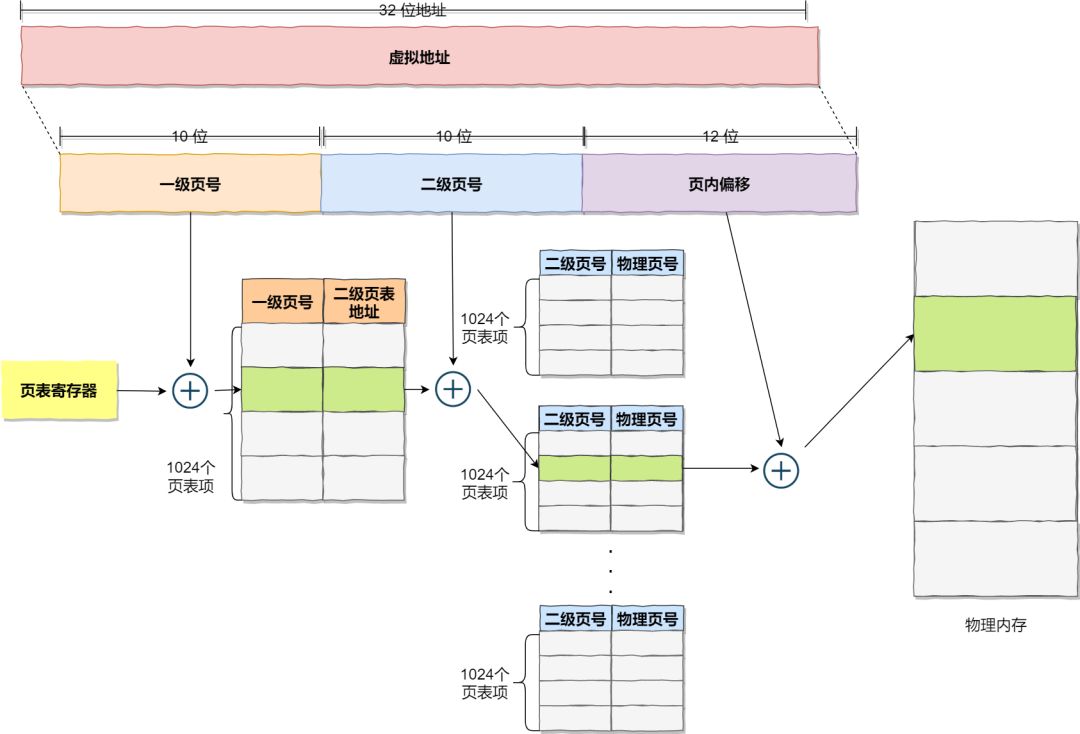
- 段页机制
进程空间管理
-
32位
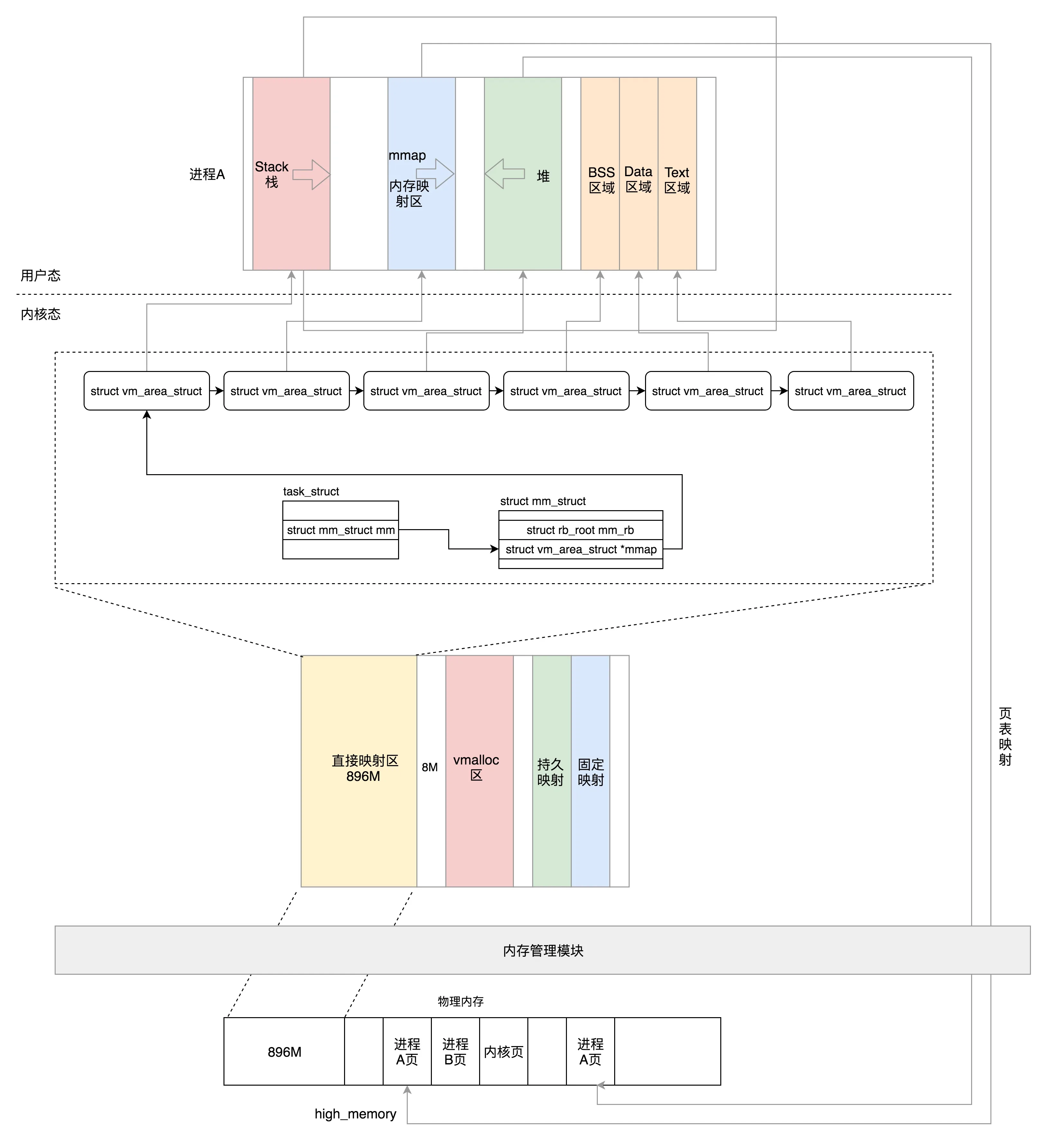
-
64位
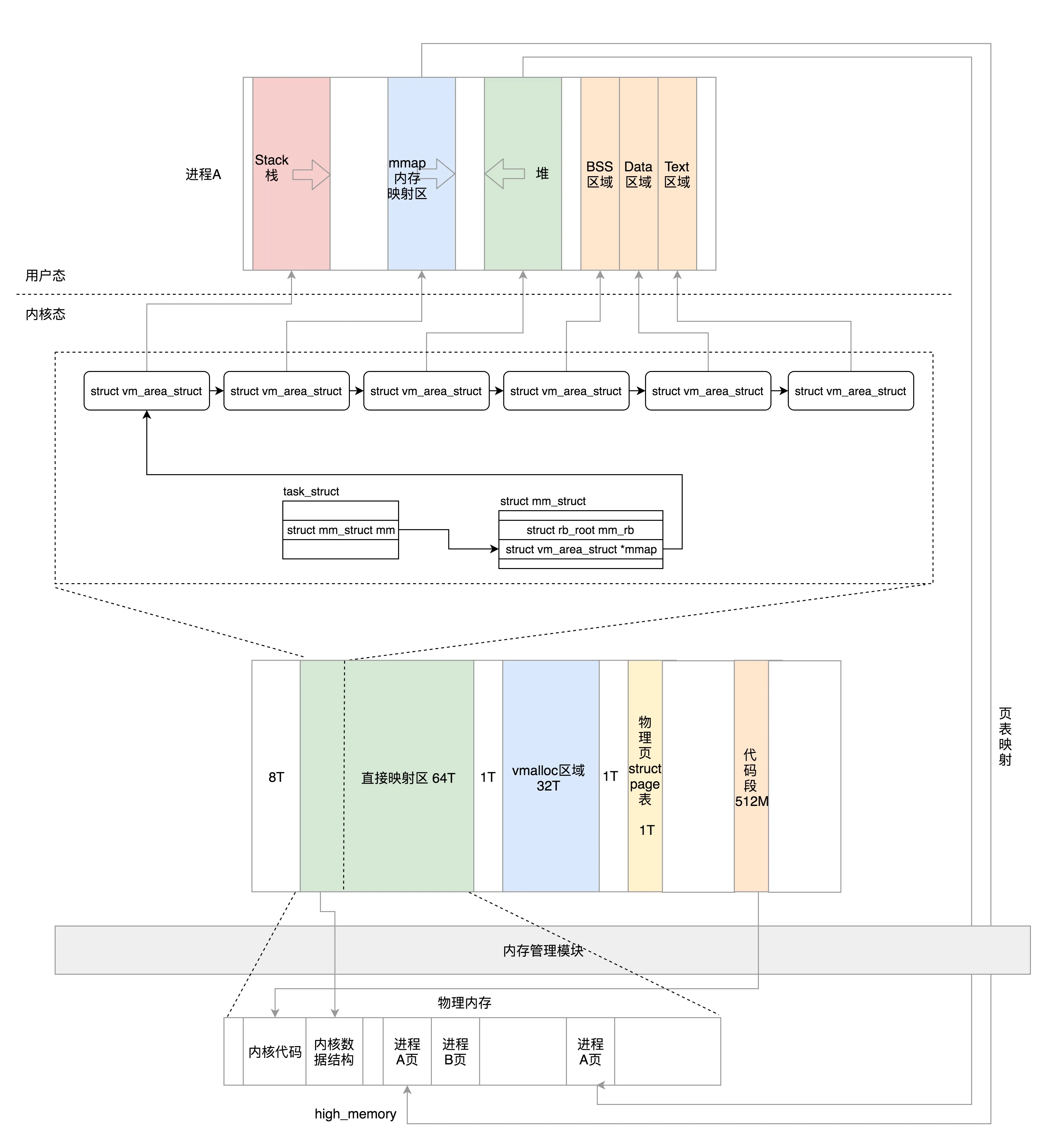
直接映射区: 这一块空间是连续的,和物理内存是非常简单的映射关系
vmalloc: 内核动态映射空间 类似用户空间的malloc
持久内核映射: 对应物理内存的高端内存
固定映射区域: 满足特殊需求
查看虚拟内存和物理内存的映射关系
cat /proc/pid/pagemap
cat /proc/kpagecount
cat /proc/kpageflags
cat /proc/kpagecgroup
物理内存
组织方式
- 平坦内存模型(Flat Memory Model)从 0 开始对物理页编号
- 对称多处理器 (Symmetric multiprocessing) 所有的 CPU 访问内存都要过总线 总线会成为瓶颈
- 非一致内存访问 (Non-uniform memory access) NUMA
NUMA 详情
当前的主流场景。
内存不是一整块。每个 CPU 都有自己的本地内存,CPU 访问本地内存不用过总线,在本地内存不足的情况下,每个 CPU 都可以去另外的 NUMA 节点申请内存。
-
节点
-
区域
-
DMA 直接内存存取
CPU 只需向 DMA 控制器下达指令,让 DMA 控制器来处理数据的传送,数据传送完毕再把信息反馈给 CPU,这样就可以解放 CPU
-
直接映射区
-
高端内存区
-
可移动区域 避免内存碎片
-
-
页 物理内存的基本单位
分配方式:
- 整页分配
- 将页划分成多个小块的存储池
- slab 利用队列
- slub 使用队列
- slob 嵌入式
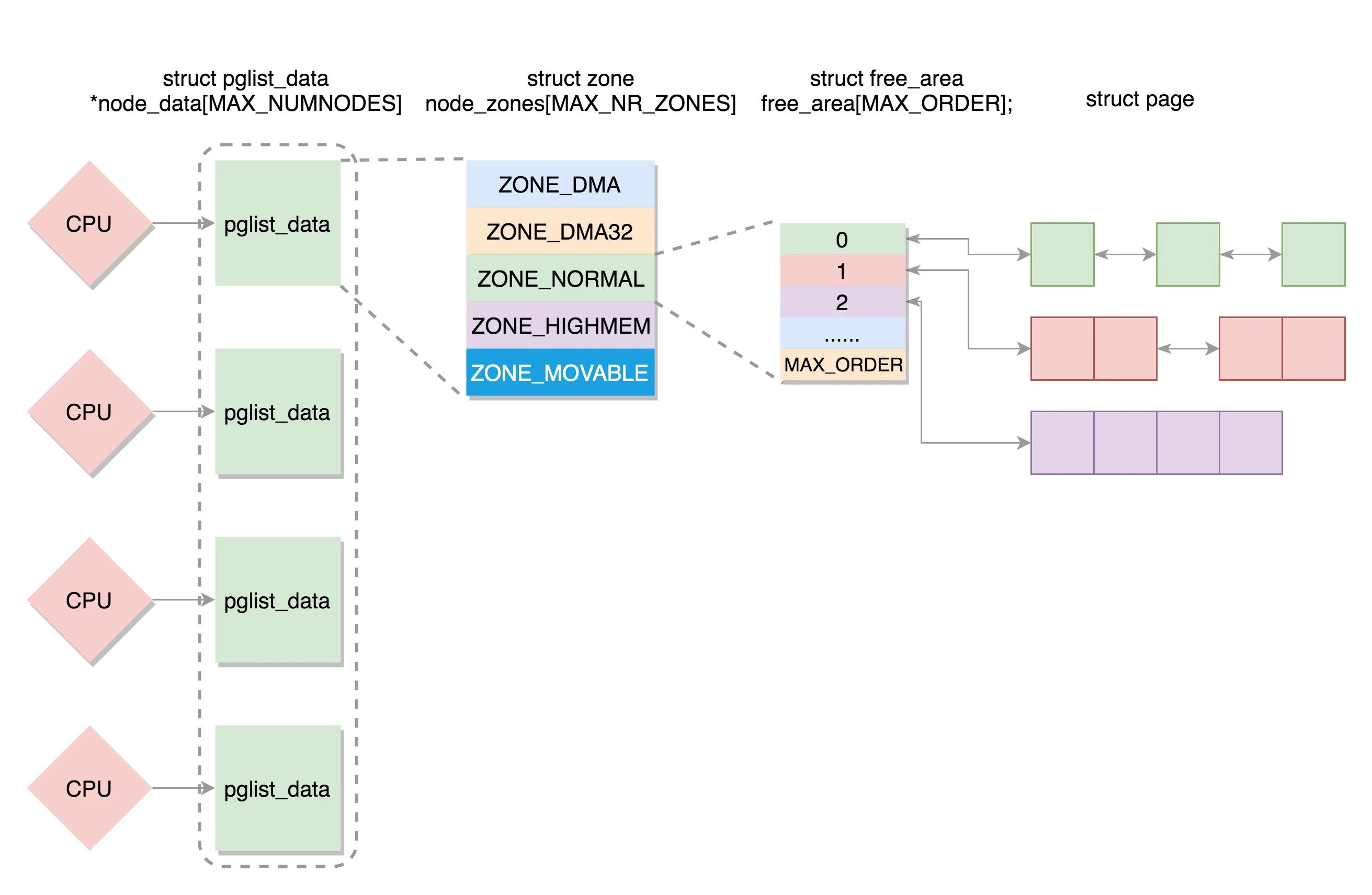
伙伴系统(buddy)
Linux 中的内存管理的“页”大小为 4KB。把所有的空闲页分组为 11 个页块链表,每个块链表分别包含很多个大小的页块,有 1、2、4、8、16、32、64、128、256、512 和 1024 个连续页的页块。
每次分配内存的时候,优先从对应大小的页块链表去找空间的页块,如果找不到,则去更大的页块中去找页块,并将其拆分到可以分配,将未分配的加入到新的链表中去。
-
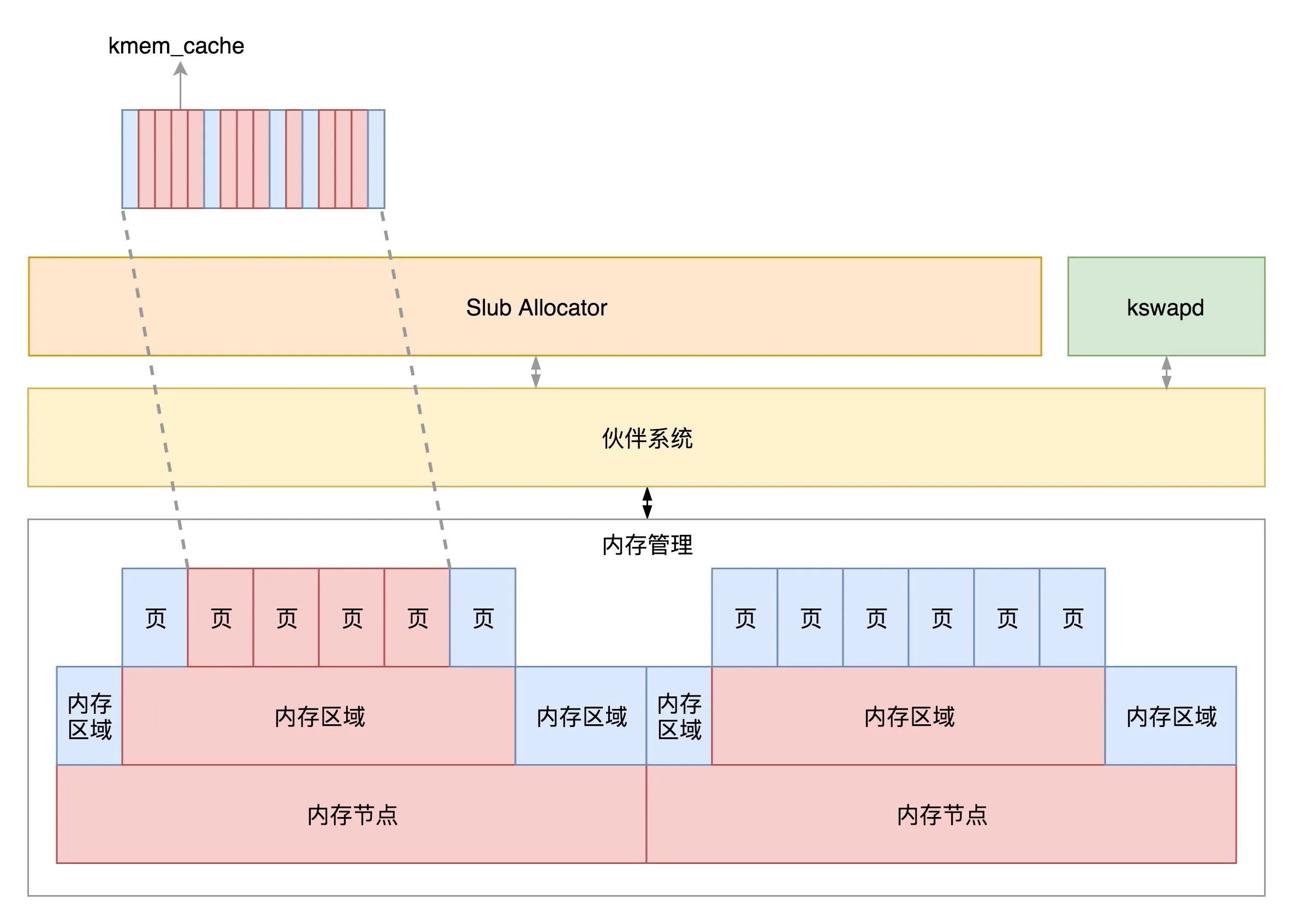
kswapd 负责物理页面的换入换出 内核线程,在系统初始化的时候就被创建
-
Slub Allocator 将从伙伴系统申请的大内存块切成小块,分配给其他系统。
- 缓存
- fast path 对应 struct kmem_cache 中的 kmem_cache_cpu
- slow path 对应 struct kmem_cache 中的 kmem_cache_node
- 缓存
用户态内存映射
- 用户态内存映射函数 mmap,包括用它来做匿名映射和文件映射。
- 用户态的页表结构,存储位置在 mm_struct 中。
- 在用户态访问没有映射的内存会引发缺页异常,分配物理页表、补齐页表。如果是匿名映射则分配物理内存;如果是 swap,则将 swap 文件读入;如果是文件映射,则将文件读入。
内核态内存映射
-
内核态内存映射函数 vmalloc、kmap_atomic
kmap_atomic 没有页表的时候,就直接创建页表进行映射
vmalloc 它只分配了内核的虚拟地址 访问它的时候,会产生缺页异常
-
内核态页表是放在 init_top_pgt,定义在 __INITDATA里面
-
内核态缺页异常
do_page_fault -> vmalloc_fault