需求背景
Kafka RoundRobin 不保证消息全局顺序一致性 而业务依赖特定顺序。
同时业务上也要求延迟处理。(这个可以在返回数据时控制)
引入 延迟队列来解决这个问题, 就是说在收到结束消息的一段时间后, 再来处理聚合的任务。
实现方式
采用 bull 来实现延迟队列。 代码如下:
bull.ts
import Bull = require("bull");
import { bullCfg, redisCfg } from "./config";
const queue = new Bull('delay-queue', {
prefix: bullCfg.prefix,
redis: redisCfg,
defaultJobOptions: {
delay: bullCfg.delay
}
});
// consumer
export async function produce(job: Job){
return queue.add(job);
}
// producer
export async function consume(){
queue.process(job => {
console.log(job.data);
});
}
确实是相当的简单和好用,但是背后的原理是什么呢?
Bull 实现
抽象:
Queue队列 ->mata-key in redisWorker处理作业的工作进程 ->processJob队列里的作业 ->data in redis
生命周期:
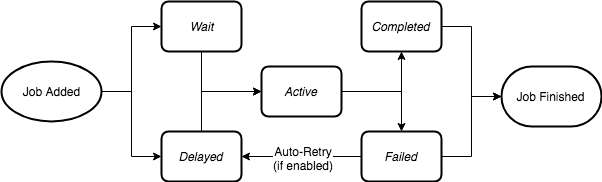
数据结构
对于任务来说, 其不同生命阶段其 jobId 存在于不同的数据结构里,有点类似 linux 进程状态
- wait (list) 等待被加入到可执行
- active (list) 可执行 -> 交给
Worker处理 - delayed (zset) 延期执行的任务 -> 满足条件后加入到
Wait状态 - priority (zset) 支持按照优先级调度的任务
- completed (zset) 已完成的任务
- failed (zset) 已失败的任务 会在一定时间后重试
具体实现
这是对源码中 针对延迟任务的简化描述
-
addJob- 执行时机
consumer.addJob
- 具体实现
-- 递增任务计数器 local rcall = redis.call local jobCounter = rcall("INCR", "id") -- 生成一个唯一的jobId, 将任务数据存在对应的 hash 对象里 rcall("HMSET", jobIdKey, "name", jobName, "data", jobData, "opts", opts, "timestamp", timestamp, "delay", delay) -- 对于延期的任务,计算出时间戳,将其加入到 delay 的 zset 里, 将最新的延期时间同步到 worker if(delay ~= 0) then local timestamp = delayedTimestamp * 0x1000 + bit.band(jobCounter, 0xfff) rcall("ZADD", "delayed", timestamp, jobId) rcall("PUBLISH", "delayed", delayedTimestamp) else -- 加入到 wait 队列, 通知到 workers rcall("LPUSH", "wait", jobId) rcall("PUBLISH", "waiting@token", jobId) - 执行时机
-
updateDelaySet- 执行时机
- Worker的 process 调用时会初始化一个定时器
- process时 当前时间 小于 已知的下一个延期事件的时间
- 具体实现
-- 按照时间戳获取 delayed 中 0 到 当前时间至多1000个 jobId local jobs = rcall("ZRANGEBYSCORE", "delayed", 0, tonumber(now) * 0x1000, "LIMIT", 0, 1000) if(#jobs >0) then rcall("ZREM", "delayed", unpack(jobs)) for _, jobId in ipairs(jobs) do rcall("LPUSH", "wait", jobId) -- 通知 workers 有新的 jobId rcall("PUBLISH","waiting@token", jobId) -- 清空 job 的 delay 字段 rcall("HSET", jobKey, "delay", 0)
- 执行时机
-
moveToActive
- 执行时机
consumer.process之前
- 具体实现
-- 从 wait 队列中取出一个放到 active 队列 local jobId = rcall("RPOPLPUSH", "wait", "active") if jobId then -- 获取锁 rcall("SET", lockKey, lockToken, "PX", lockDuration) -- 通知worker有active的job rcall("PUBLISH", "active", jobId) -- 记录开始处理的事件 rcall("HSET", jobKey, "processedOn", now) -- 返回 job return {rcall("HGETALL", jobKey), jobId} else -- 通知 worker 无数据需要处理 rcall("PUBLISH", "drained", "") end
- 执行时机
-
consumer.processJob-
执行时机 执行具体的业务逻辑
-
具体实现
this.delayedTimestamp = nextTimestamp? nextTimestamp / 4096 : Number.MAX_VALUE; // Clear any existing update delay timer if (this.delayTimer) { clearTimeout(this.delayTimer); } // Delay for the next update of delay set const delay = _.min([ this.delayedTimestamp - Date.now(), this.settings.guardInterval ]); // Schedule next processing of the delayed jobs if (delay <= 0) { // Next set of jobs are due right now, process them also this.updateDelayTimer(); } else { // Update the delay set when the next job is due // or the next guard time this.delayTimer = setTimeout(() => this.updateDelayTimer(), delay); }
-
-
moveToFinished/moveToFail- 执行时机
processJob完成以后
- 具体实现
-- 释放锁 if lockToken ~= "0" then if rcall("GET", lockKey) == lockToken then rcall("DEL", lockKey) else return -2 end end -- 从 active 列表中移除 rcall("LREM", "active", -1, jobId) -- 通知 worker 任务完成 rcall("PUBLISH", completeKey, jobId); return 0这个实现有哪些好处呢
1. 通过 `PUBLISH / SUBSCRIBE` 通知的机制来实现减少轮询的, 从而降低 `CPU` 使用率 2. `active` 和 `waiting` 的分离,从而便于实现自定义的调度(延迟,重复,优先级) 3. 可以实现对于失败 `job` 的重试 4. 和 node 语言相关的优化 - 支持沙盒进程,从而更好的利用多核
CPU,也避免了单个进程崩溃影响其他作业 - 支持
concurrency参数,在IO密集型的场景下可以提高并发 - 通过
EventEmitter暴露出对 各个阶段的事件的扩展能力
- 执行时机
隐藏的坑点
- 原子性 所以上面的步骤都需要
lua脚本执行 - 集群场景下
lua脚本需要所涉及到的key在同一个节点上 ->prefix使用{hashtag} redis默认淘汰策略maxmemory-policy=noeviction
bull 是否能被称为消息队列呢
消息队列的基本要求都满足吗?
- 消息的可靠传递:确保不丢消息;
Cluster:支持集群,确保不会因为某个节点宕机导致服务不可用,当然也不能丢消息;- 性能:具备足够好的性能,能满足绝大多数场景的性能要求。
重复消费的处理属于以下哪种呢?
At most once消息在传递时,最多会被送达一次。换一个说法就是,没什么消息可靠性保证,允许丢消息。At least once至少一次。消息在传递时,至少会被送达一次。也就是说,不允许丢消息,但是允许有少量重复消息出现。(幂等)Exactly once恰好一次。消息在传递时,只会被送达一次,不允许丢失也不允许重复,这个是最高的等级。